Production-grade hail damage detection API.
Integrate computer vision into your pipeline in minutes. Enterprise SLA, sub-50ms inference times, and built for scale. Stop managing deployed models.
Computer vision at scale is an infrastructure problem.
Deploying ML models in production requires managing GPU instances, setting up load balancers, handling versioning, and wrestling with CUDA dependencies. We handle the infrastructure so your team can focus on consuming accurate inferences.
Zero Infrastructure
No VMs to configure, no containers to optimize, and no GPU drivers to update. Simply send your image via our REST API and receive low-latency structured JSON responses.
Auto-Scaling Compute
Handle a single image or a massive batch without manual capacity planning. Our distributed inference clusters absorb traffic spikes automatically while maintaining SLA.
Deterministic Accuracy
Built on state-of-the-art vision foundations and fine-tuned on millions of proprietary samples. Get predictable, highly accurate bounding boxes and severity metrics every time.
Integration in three steps.
A developer-first experience designed to get you from signup to your first production inference in under 5 minutes.
Authenticate
Attach your API key as a Bearer token. Use secret keys (hail_live_) for server-side or publishable keys (hail_pub_) for frontend with origin locking.
curl -H "Authorization: Bearer hail_live_..." \
https://hailapi.com/api/v1/detectSubmit Image
Send car panel images via multipart/form-data. Supports JPEG, PNG, WebP up to 10MB. Batch up to 10 images in a single request.
const form = new FormData();
form.append('image', file);
const res = await fetch(
'https://hailapi.com/api/v1/detect',
{
method: 'POST',
headers: { Authorization: 'Bearer ...' },
body: form
}
);Get Results
Receive structured JSON with detections, severity breakdown, damage score, and optional diameter estimation via nozzle calibration.
// Response
{
"data": [{
"data": {
"summary": { "total_haildents": 12 },
"analysis": {
"damage_score": 42,
"by_severity": {
"small": 5, "medium": 5, "large": 2
},
"density": "moderate"
}
}
}]
}See the unseen damage instantly.
Our models return highly structured JSON containing the precise coordinates, diameter estimates, and severity of every hail dent on the panel. The visualization below demonstrates the level of detail our API can extract from a single image in under 50ms.
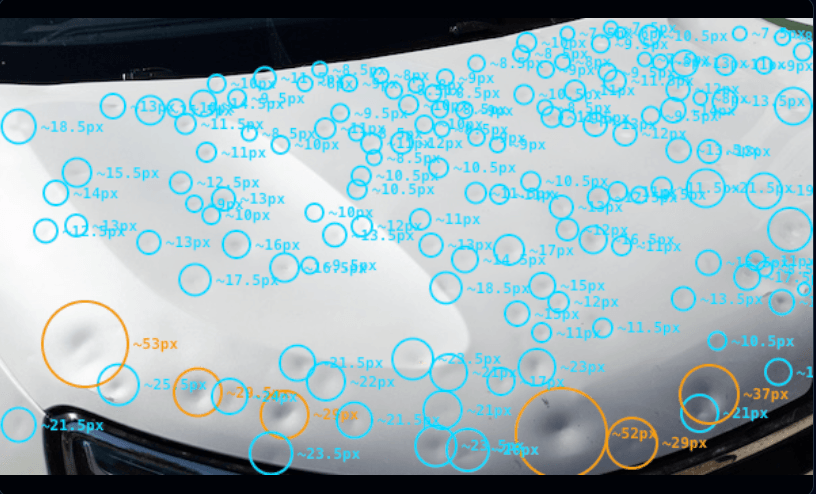
Built for production workloads.
We provide the primitives you need to build reliable applications. No marketing fluff, just robust features that solve real pain points.
Ed25519 Bearer Auth
Stateless, cryptographically secure edge authentication with robust token revocation and granular scoping.
Dynamic Rate Limiting
Redis-backed token bucket algorithm ensuring predictable throughput without aggressive cutoff cliffs.
Idempotent Webhooks
Guaranteed delivery with exponential backoff. Every payload is signed with a secret hash for verification.
Sub-50ms Inference
Hardware-accelerated NCNN instances optimized for image tensors reduce round-trip latency effectively.
Structured Logging
Pipe inference logs directly to Datadog, Splunk, or custom S3 buckets. Full observability out-of-the-box.
99.99% Guaranteed SLA
Enterprise-backed reliability. We run multi-region active-active clusters to mitigate any regional cloud outages.
Trusted by Engineering Teams
Processing over 12M+ images monthly.
"We migrated from our in-house Vertex AI deployment to HailAPI. The P99 latency dropped from 400ms to 65ms, and we stopped worrying about instance scaling during storm seasons."
Marcus K.
Principal Engineer, AutoClaim
"The structured JSON output with exact bounding box coordinates allowed us to overlay damage heatmaps directly onto our app. The Webhook delivery is flawless."
Sarah J.
CTO, InspectFlow
"We were spending $4k/month on idle GPUs. Switching to HailAPI's usage-based model cut our inference costs by 70% while improving detection accuracy by ~12%."
David R.
Lead Dev, FleetLogic
Pay-as-you-go compute.
A purely consumption-based model. No subscriptions, no hidden egress fees, no instance minimums. Top up your wallet and pay only for successful inferences.
Usage-based Pricing
Add funds to your wallet to start using the API. Your credits never expire and rate limits scale automatically with your usage.
What's included
- Non-expiring creditsFunds stay in your wallet until you use them.
- Auto-scaling rate limitsLimits automatically increase based on your wallet balance and usage history.
- Pay for success onlyFailed requests or invalid images are never charged to your account.
Start identifying hail damage today.
Get your API keys instantly. $7.50 free credit (50 scans) to start. No credit card required.